AMMs were literally invented for prediction markets. Robin Hanson designed market scoring rules as a way to bootstrap liquidity for forecasting platforms in the early 2000s. Those scoring rules became the mathematical ancestors of every CPMM and LMSR deployed in DeFi today. So it’s a strange irony that Paradigm researchers noted in late 2024 that most of the prediction market volume taking off in crypto uses order books, not AMMs. The reason is structural: existing AMMs are a poor fit for outcome tokens, which behave fundamentally differently from the token pairs AMMs were re-optimized for in DeFi. Understanding why that is, what LMSR does differently, and where the research is heading in 2026 is the difference between building a prediction platform that works and one that silently bleeds LP capital until no one provides liquidity.
Why Standard CPMM Fails Outcome Tokens

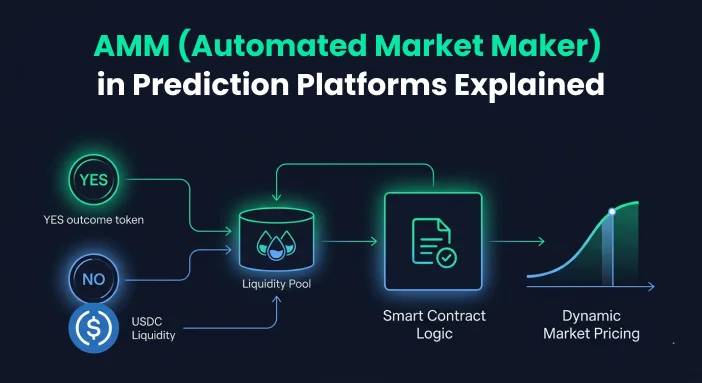
The constant product formula (x * y = k) is the most deployed AMM invariant in DeFi. Uniswap pioneered it. For token swaps between assets without a known terminal value, it works well. Outcome tokens are different.
A YES token for a binary prediction market doesn’t behave like ETH or USDC. Its price is bounded between 0 and $1.00. Its volatility is a function of new information about the specific event the market tracks. And critically, at expiry, it resolves to exactly $1.00 or exactly $0.00. There is no middle ground.
A standard CPMM pool holding YES and NO tokens for a binary market has an uncomfortable property: LP losses are guaranteed under informed trading. As the market converges toward a known outcome (YES becomes near-certain), informed traders buy YES tokens from the pool at prices below $1.00. The LP is on the other side of every single one of those trades. By the time the market resolves, the LP has sold YES tokens at below-terminal-value prices and holds mostly NO tokens worth $0.00. This isn’t impermanent loss in the usual DeFi sense. It’s a guaranteed loss that gets worse the more accurate the market’s crowd intelligence becomes.
One prediction platform launched with a pure CPMM AMM on their binary markets. Their LPs seeded $400,000 at launch. Within six weeks, informed trading had extracted roughly $60,000 in value from the pool through systematically buying YES tokens at below-terminal prices before three high-certainty political events resolved. The LPs withdrew and didn’t return. The platform relaunched with LMSR six months later.
For a full walkthrough of how to build a prediction platform that avoids this problem, see how to build a prediction market platform like Polymarket.
LMSR: The AMM Built for Binary Markets
Logarithmic Market Scoring Rule (LMSR) was designed by Robin Hanson specifically for prediction markets in 2003. It predates Uniswap by over a decade. The key property that distinguishes it from CPMM is bounded LP loss.
The LMSR cost function prices shares according to:
C(q_yes, q_no) = b * ln(e^(q_yes/b) + e^(q_no/b))
where b is the liquidity parameter set at market creation. The implied probability of YES maps through the logistic function to the range (0, 1) — exactly the shape you want for a market tracking an event probability.
The bounded loss property follows from this structure. In the worst case, the LP’s total loss is bounded at b * ln(2). With a liquidity parameter of 10,000 USDC, the maximum LP loss is approximately $6,931. That’s a predictable, capped downside that makes seeding a market a financially rational decision for a platform operator.
LMSR is more expensive per trade in gas than CPMM because it requires computing logarithms and exponentials on-chain. On Polygon or Arbitrum, this adds under $0.01 per transaction. On Ethereum mainnet, it adds meaningful friction — one more reason mainnet is the wrong chain for consumer prediction markets.
LMSR also has a limitation most implementations don’t document: the liquidity parameter b is fixed at market creation. You can’t add liquidity to a running LMSR market without changing b, which changes all the prices. This makes it harder to incentivize ongoing liquidity provision as a market gains traction. It works well for platform-seeded markets. It’s harder to adapt for community-provided liquidity.
The LP Loss-at-Expiry Problem
Even LMSR doesn’t fully solve what Paradigm’s researchers called the “LP loss-at-expiry” problem. The issue is structural to any AMM for prediction markets.
As a prediction market approaches its resolution date, the outcome becomes increasingly certain. A market that started at 50/50 odds might move to 95/5 odds in the final hours. At that point, the AMM’s YES token pool is nearly depleted and the remaining LP capital sits mostly in near-worthless NO tokens. Settlement comes, NO resolves at zero, and the LP absorbs the terminal loss.
This is different from impermanent loss in a standard token AMM. With ETH/USDC, impermanent loss is recoverable — prices can revert and LPs recoup their position. With outcome tokens, there is no reversion. The market resolves once. The LP can’t wait for price recovery.
The practical consequence is that LPs who experience this once either demand higher fees to compensate, shift capital to markets near 50/50 where terminal loss risk is lower, or stop providing liquidity entirely. Platforms that don’t address this mechanism lose LP capital after their first few markets resolve.
Mitigation approaches include time-weighted fee schedules (fees increase as the market approaches expiry to compensate LPs for increasing terminal risk), LP withdrawal windows that close before the final resolution period to prevent adverse selection in the last hours, and dynamic b parameters that reduce pool depth as outcome certainty increases. None of these are standard in off-the-shelf prediction market scripts.
pm-AMM and Gaussian Score Dynamics
In November 2024, Paradigm researchers published a paper introducing the pm-AMM: an AMM specifically designed for prediction markets using what they call Gaussian score dynamics. It’s the most significant AMM research for prediction markets since LMSR, and most 2026 platform articles haven’t caught up to it yet.
The core insight is that existing AMMs (including LMSR) don’t model how information arrives in a prediction market over time. LMSR treats each trade independently. But in a real prediction market, the rate at which new information changes the outcome probability follows patterns that depend on the event type. Sports games release information continuously through scoring. Elections release information in concentrated bursts. Earnings announcements are binary information events.
The Gaussian score dynamics model assumes that the log-odds of an event evolve according to a Brownian motion with known variance over time. From this model, Paradigm derives an AMM invariant calibrated to the specific information dynamics of the market. The result is a uniform AMM: LPs receive the same expected fee rate per unit of risk across all price levels. Neither CPMM nor LMSR achieves this uniformity.
The paper notes the model fits some market types better than others. Basketball games are a good fit because scoring is frequent and the score differential evolves predictably. Soccer games are a worse fit because scoring is rare and lumpy. Single-occurrence surprise events don’t fit the Gaussian model at all.
For startup founders in 2026: don’t deploy pm-AMM in production yet. It hasn’t been audited at scale and the implementation complexity is significantly higher than LMSR. But it signals where the standard likely shifts in 2027 to 2028.
The Cold-Start Liquidity Problem and How to Solve It
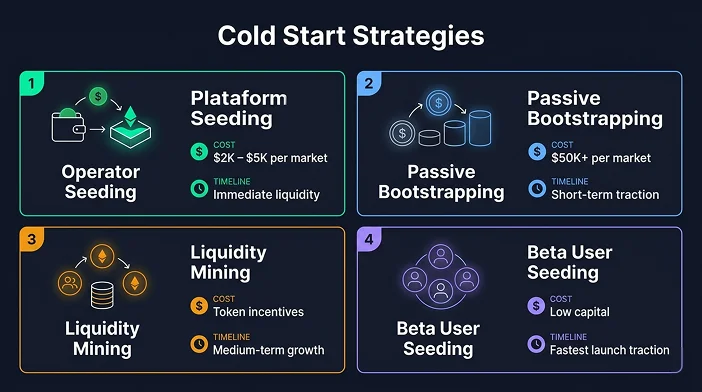
Every prediction market AMM faces the same day-one problem: an empty pool is a dead market. A user who opens a market with no liquidity sees spreads so wide that buying YES at 52 cents and selling at 48 cents is the best available execution. They leave immediately. The cold-start problem is the biggest operational reason prediction platforms fail in their first 90 days.
Operator-seeded liquidity is the simplest solution. The platform deposits USDC into every new market at creation to seed the LMSR pool with a predefined b parameter. This guarantees minimum liquidity but commits platform capital. Budget $2,000 to $5,000 per market for meaningful initial depth. For 50 active markets simultaneously, that’s $100,000 to $250,000 in working capital tied to liquidity pools.
Passive liquidity bootstrapping concentrates capital in a small number of high-quality markets rather than spreading thin. Three markets with $50,000 each feel alive and attract users. Thirty markets with $5,000 each all feel thin and drive users away. Start with depth, not breadth.
Liquidity mining programs incentivize external LP deposits by distributing platform governance tokens proportional to LP share and time in pool. This works if your governance token has value. Don’t rely on it to solve cold start. It’s a scale solution, not a launch solution.
Hybrid seeding through community waitlists uses 200 to 500 closed beta users to generate initial trading activity before public launch. This creates visible activity, tighter spreads, and meaningful implied probabilities by the time organic users arrive. It’s the fastest and cheapest cold-start mitigation for a capital-constrained early-stage platform.
AMM vs CLOB: When to Switch and Why
The honest answer is that AMMs work at launch and CLOBs work at scale. The decision is a function of trading volume, not ideology.
Below roughly 1,000 daily active traders, an AMM wins on every practical metric. It guarantees execution at any time without requiring matched counterparties. A CLOB with 200 daily users has an order book that feels empty, orders that sit unfilled for hours, and users who assume the platform is broken.
Above roughly 2,000 to 3,000 daily active traders, a CLOB starts to pull ahead. Professional traders prefer order books because they enable limit orders, layered bid/ask structures, and precise position sizing. The spread tightens as market makers compete. Price discovery improves because traders express intent at specific prices rather than accepting whatever the AMM formula quotes.
The operational cost of a CLOB is significantly higher. You need an off-chain matching engine (Node.js or Go with Redis-backed order books), settlement batching infrastructure, WebSocket order book streams for sub-100ms updates, and a rate limiting layer that handles automated trading traffic. This is a version two project, not a launch project.
| Factor | AMM (LMSR) | CLOB | Hybrid |
|---|---|---|---|
| Launch complexity | Low | High | Medium |
| Works at low volume | Yes | No | Yes |
| LP loss risk | Bounded (b*ln(2)) | None | Bounded |
| Price discovery | Good | Best | Best |
| Infrastructure cost | Low | High | Medium-High |
| Right for | Launch, <1K DAU | Scale, 2K+ DAU | Production growth phase |
Hybrid AMM Architectures: Manifold and Polymarket
Manifold runs what their API exposes as cpmm-1 and cpmm-multi-1 for multi-outcome markets. Their market engine fills limit orders first and routes the remainder to the AMM pool. The CPMM parameterization they use is y^p * n^(1-p) = k, a generalization that allows asymmetric initial pricing rather than forcing every market to start at 50/50.
Polymarket’s CLOB sits on top of the Gnosis Conditional Tokens Framework, which handles collateral and outcome token accounting. The CTF manages splitPosition, mergePositions, and redeemPositions, but the trading layer above it is a pure CLOB. Polymarket gets the accounting elegance of the CTF with the execution performance of a centralized order book.
For a startup building in 2026: launch with LMSR AMM seeded by operator capital, add limit order functionality as volume grows, and build toward a hybrid CLOB after you’ve validated 2,000-plus daily active users. Don’t start with a CLOB. Build toward it.
Frequently Asked Questions
Q1: Why doesn’t Uniswap’s x*y=k formula work for prediction markets?
Constant product AMMs have guaranteed LP loss on binary outcome tokens. As a market moves toward near-certainty (YES at 95 cents), informed traders systematically extract value by buying YES from the pool at below-terminal prices. The LP ends up holding mostly worthless NO tokens after resolution. LMSR prevents this by bounding maximum LP loss at b * ln(2) regardless of outcome skew. Impermanent loss in standard DEXes can recover as prices revert. In prediction markets, resolution is terminal. There is no recovery.
Q2: What is the liquidity parameter b in LMSR and how do I set it?
b determines both maximum LP loss and market depth. Higher b means deeper liquidity (less slippage on large trades) but more operator capital at risk. With b = 10,000 USDC, maximum LP loss is about $6,931 and a 1,000 USDC trade moves the implied probability by roughly 5 to 10 percentage points. For a startup seeding initial markets, b between 5,000 and 15,000 USDC per market is a reasonable starting range depending on expected trading volume.
Q3: What is Loss-versus-Rebalancing (LVR) in prediction market AMMs?
LVR is the expected loss an AMM LP incurs from providing liquidity to informed traders who systematically know more than the pool’s current price reflects. In prediction markets, LVR is amplified by terminal resolution: all the information advantage that informed traders extract converges into a single settlement event where the LP’s residual position has deterministic value. This is the structural reason why LP economics in prediction markets are harder than in standard token AMMs.
Q4: What is the pm-AMM and should I use it in 2026?
Paradigm’s pm-AMM (2024) uses Gaussian score dynamics to model how information arrives in a prediction market over time and derives an AMM invariant calibrated to those dynamics. It achieves better LP fee distribution than LMSR for market types where information arrives continuously (sports, financial markets). It’s not production-tested at scale and carries significant implementation complexity. Don’t use it for a 2026 launch. It likely represents where the standard shifts in 2027 to 2028.
Q5: How many daily users do I need before switching from AMM to CLOB?
A CLOB starts to outperform an AMM at roughly 1,000 to 2,000 daily active traders. Below that, the order book feels empty and users interpret inactivity as a broken product. Above 2,000 to 3,000, professional market makers arrive organically and price discovery improves. Track daily active traders, not sign-ups. Most platforms see sign-ups 5x to 10x their daily active count.
Q6: How do LP fees work in a prediction market AMM?
Each trade against the pool pays a fee (typically 1% to 3%) distributed to liquidity providers proportional to their pool share. In an LMSR pool, fees are added on top of the LMSR cost function. In a CPMM pool, fees are taken as a percentage before the swap calculation. Fees alone are usually insufficient to compensate for terminal LP loss on high-certainty markets. This is why operator liquidity mining subsidies are common in the first 6 to 12 months of a new platform.
Q7: Can a prediction market AMM run fully on-chain?
Yes. Both LMSR and CPMM are fully on-chain smart contract implementations. Every trade, price update, and fee distribution happens on-chain with no off-chain components. The tradeoff is latency (2 to 12 seconds on Polygon) and gas costs. For real-time trading, a hybrid approach (off-chain matching, on-chain settlement) reduces latency to under 100ms while preserving non-custodial security. Full on-chain AMM is appropriate for lower-frequency markets where users accept blockchain transaction speeds.




